




百度于 6 月 22 日发布了其开源的 Unlimited OCR 模型,该模型拥有 30 亿的总参数,但在推理过程中仅激活 5 亿参数。此举旨在解决端到端 OCR 模型在处理长文档时,因生成过程变慢而带来的效率问题。
作为一种统一的神经网络架构,端到端 OCR 模型集成了文本检测与字符识别功能,省去了传统方法中先框选文本再进行识别的复杂步骤,能够直接将图像输入转化为文本序列输出,从而减少了信息损失和计算上的冗余。
现有的大多数端到端 OCR 模型在生成每个 token 时都会增加 KV cache 的规模,导致显存占用和延迟不断升高。这使得用户在 AI 处理多页文档时,会明显感觉到速度逐渐变慢,这就像足球运动员在参加2026世界杯预选赛时,越到关键时刻越感到疲惫。
Unlimited OCR 模型沿用了 DeepSeek OCR 的架构设计,保留了 DeepEncoder 和 Mixture-of-Experts(MoE)解码器。其总计 30 亿的参数量中,推理阶段仅会启用 5 亿。
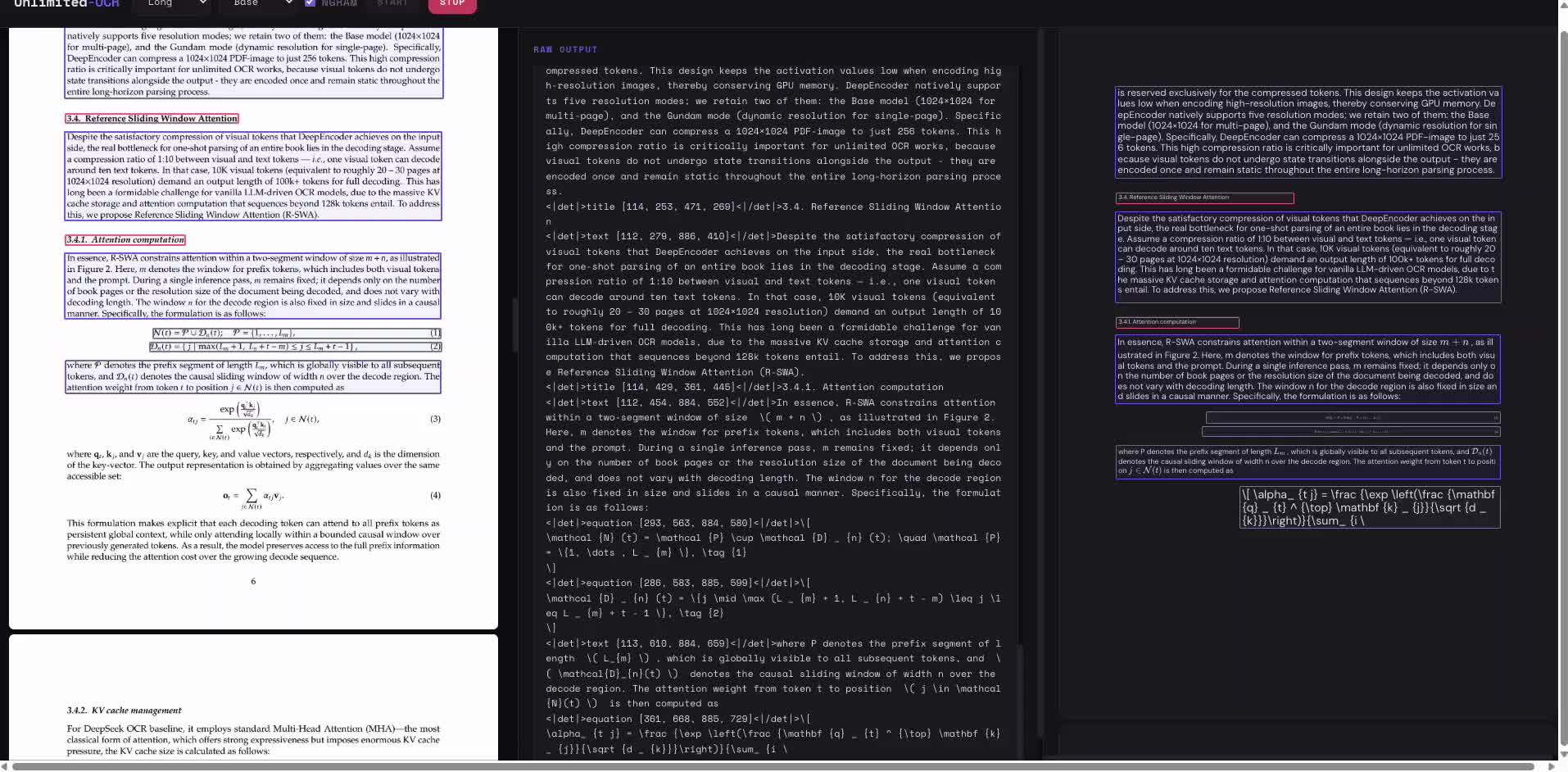
在编码方面,Unlimited OCR 采用了两级视觉编码机制,并在连接阶段实现了 16 倍的 token 压缩。这意味着,一张 1024×1024 分辨率的 PDF 图像会被压缩成 256 个视觉 token,从根本上减轻了预填充所带来的负担。
在模型训练过程中,Unlimited OCR 是在 DeepSeek OCR 的基础上继续训练了 4000 步。训练过程中,DeepEncoder 被冻结,仅对解码器进行训练。训练数据集包含了约 200 万份文档样本,该过程在 8 块 A800 GPU 上完成。训练数据的构成比例为单页文档和多页文档约 9:1,其中多页样本是通过拼接方式生成的。
基准测试结果显示,Unlimited OCR 在 OmniDocBench v1.5 上的综合得分达到了 93.23,优于 DeepSeek OCR 的 87.01 和 DeepSeek OCR 2 的 89.17。
具体性能指标方面,该模型在文本编辑距离上为 0.038,公式 CDM 得分为 92.61,表格 TEDS 评分为 90.93,读序编辑距离为 0.045。在 OmniDocBench v1.6 的测试中,Unlimited OCR 的整体得分进一步提升至 93.92。

